
Een datamodel volgens de praktijk

In mijn tweede blog over Power BI in de praktijk van Kasparov BI pak ik het datamodel beet: een van de meest belangrijke aspecten van een goede Power BI-omgeving. Het datamodel is de weg waarop Power BI navigeert om tot een goed eindresultaat te komen. Het opstellen van een goed en efficiënt model brengt voordelen op het gebied van prestatie, DAX-codering en foutoplossingen. Opnieuw voer voor vakgenoten, voel je vrij om feedback te geven of vragen te stellen. Graag zelfs!
Voor het opzetten van een datamodel is het belangrijk om goed afgewogen keuzes te maken. Hierbij kan de volgende structuur worden aangehouden:
- Het normaliseren van tabellen
- Het definiëren van tabellen in feiten en dimensies
- Het leggen van relaties
- Het definiëren van de architectuur van het semantic-model
1. Het normaliseren van tabellen
Normalisatie
Normaliseren is een methode voor het organiseren van gegevens in een relationele database. Stel: Een tabel heeft een kolom met (unieke) waarden, bijvoorbeeld de kolomproductsleutel. Elke productsleutel heeft zijn omschrijvende waarden in bijbehorende kolommen, zoals bijvoorbeeld kleur, grootte en categorie. Alle data in één tabel kan voor onoverzichtelijkheid en overtollige data zorgen.
Het modificeren en/of splitsen van een tabel zodat deze alleen sleutelkolommen overhoudt en hierdoor de omschrijvende waarden als nieuwe tabellen aan het model toevoegen heet normaliseren. Overtollige data is hierbij geminimaliseerd en het semantic-model zal overzichtelijker en makkelijker te begrijpen zijn.
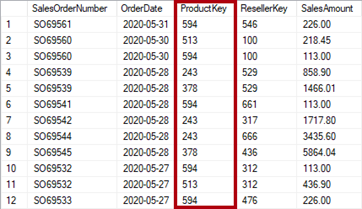
Denormalisatie
In de situatie van het normaliseren van een tabel door de omschrijvende waarden eruit te halen en in een nieuwe tabel te plaatsen, wordt in hetzelfde geval de nieuwe tabel gedenormaliseerd. Hier komen immers alle omschrijvende waarden in een tabel te staan. Denormalisatie is de toestand waarin alle gegevens, inclusief omschrijvende waarden, in één tabel staan in plaats van in afzonderlijke tabellen. Onderstaande kolom is gedenormaliseerd.
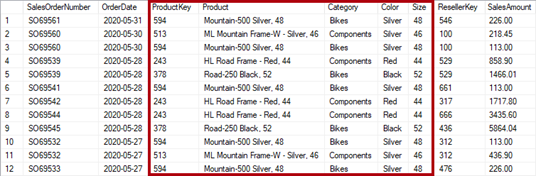
In het streven naar een efficiënt datamodel wordt geadviseerd om het datamodel zo veel mogelijk te normaliseren. Dit verkleint de kans op overtollige data en Veel-op-Veel (*:*) relaties.
2. Het definiëren van tabellen in feit en dimensie
In het proces van normalisatie worden grote gedenormaliseerde tabellen opgeknipt in meerdere kleinere tabellen. Er ontstaat een splitsing tussen dimensietabel en feitentabel.
Dimensietabel
Een dimensietabel is een tabel in een ster-, sneeuwvlok- of sterrenvlokmodel waarin omschrijvende waarden over de feiten zijn opgeslagen. Dimensietabellen bevatten data waar men mee kan opzoeken of filteren. In een dataset met data over de verkoop van auto’s staat de kleur, grootte en het merk in een dimensietabel. Die hebben vaak een sleutelkolom met unieke waarden en hangen door middel van één-op-veel (1:*) aan de feitentabel. In een stermodel zijn dimensietabellen vaak gedenormaliseerd, terwijl in een sneeuwvlokmodel de tabellen veelal zijn genormaliseerd. Zie hiervoor ook 4 – De architectuur.
Feitentabel
Een feitentabel is een tabel in een ster-, sneeuwvlok- of sterrenvlokmodel waarin data is opgeslagen waarmee je kunt rekenen of meten. In een dataset over de verkoop van auto’s staan de omzet en verkoopprijs in de feitentabel. Die bevatten vaak geen unieke waarden en hangen door middel van een veel-op-één (*:1) aan de dimensietabel.
In relatie tot Power BI
In het streven naar een efficiënt datamodel wordt geadviseerd om altijd een onderscheidende waarde mee te geven in de naam van de tabel. Dit kan een d_ zijn voor een dimensie of een f_ voor een feitentabel. Hierdoor heeft de ontwikkelaar altijd snel inzichtelijk wat het doel van de tabel is, welke tabel kan worden gebruikt als opzoek- of filterwaarden en welke tabel kan worden gebruikt om te meten of rekenen.
3. Het leggen van relaties
In het proces van normalisatie worden grote gedenormaliseerde tabellen opgeknipt in meerdere kleinere tabellen. Er ontstaat een splitsing tussen feitentabel en dimensietabel. Ze communiceren met elkaar door relaties. Om relaties goed te kunnen begrijpen, kan onderscheid worden gemaakt in twee onderdelen: kardinaliteit en filterrichting.
Kardinaliteit
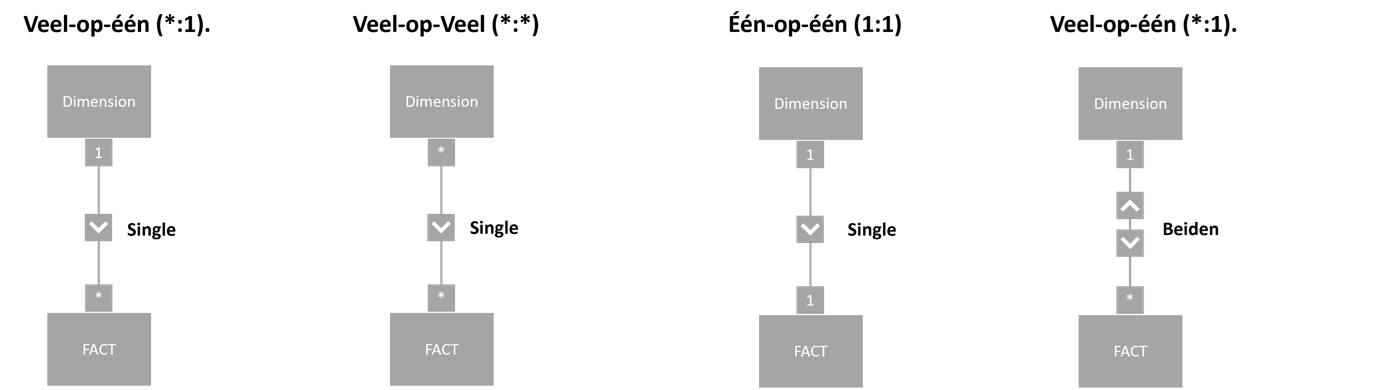
Met kardinaliteit wordt bedoeld: het aantal waarden in een tabel dat kan matchen met het aantal waarden in een andere tabel. In Power BI-begrippen zijn de volgende kardinaliteiten te onderscheiden:
Veel-op-één (*:1)
Veel-op-één betekent dat in de veel-kolom (feitentabel) een waarde meerdere keren kan voorkomen. In de één-kolom (vaak de dimensie) komt de waarde maar één keer voor. Dit is de meest voorkomende relatie en zal de beste prestaties opleveren. Power BI hoeft immers maar één waarde op te zoeken en matchen. Deze relatie wordt in beginsel altijd geadviseerd.
Één-op-één (1:1)
Één-op-één betekent dat in de veel-kolom (feitentabel) een waarde maar één keer voorkomt. In de één kolom (vaak de dimensie) komt de waarde ook maar één keer voor. Deze relatie komt zelden voor en áls ze voorkomt, kun je je afvragen of normalisering echt nodig is. Het toevoegen van een extra datatabel kost immers ook opslag.
Veel-op-Veel (*:*)
Veel-op-Veel betekent dat in de veel-kolom (feitentabel) een waarde meerdere voorkomt. In de één kolom ( vaak de dimensie ) komt de waarde ook meerdere keer voor. Al valt deze vorm van relatie niet altijd te voorkomen, wordt aangeraden ze waar mogelijk te vermijden. Bij deze vorm van relatie zal Power BI alles met alles vergelijken en hierdoor het aantal query’s op de achtergrond vermenigvuldigen. Deze relatie kan voor prestatieproblemen zorgen.
Als deze relatie niet valt te vermijden, omwille van vereisten en data, probeer dan een tussentabel te creëren. Een tussentabel is een tabel met unieke waarden die tussen de feitentabel en de dimensietabel staat. De tussentabel heeft een veel-op-één relatie met filter richting – beide met de dimensie abel en een veel-op-één relatie met de filterrichting – single met de feitentabel.
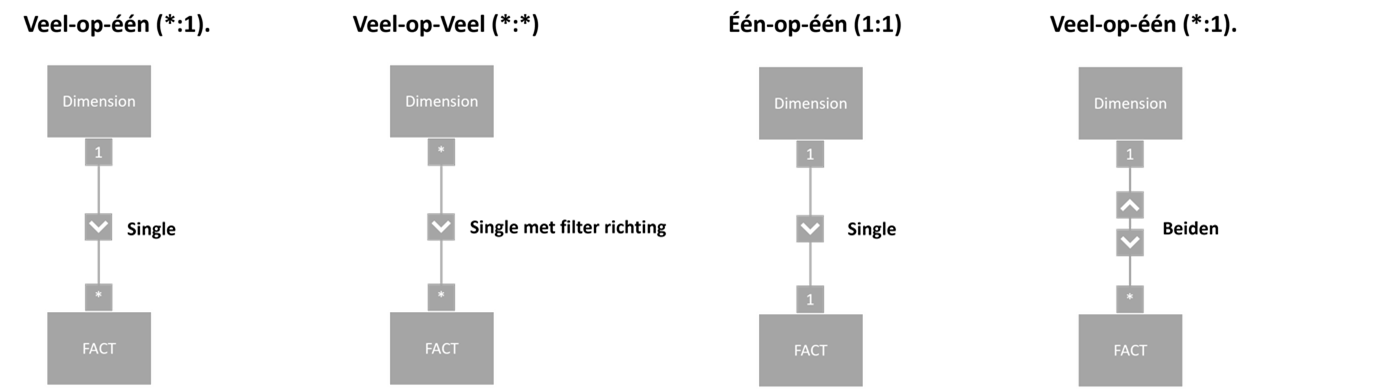
Filterrichting
Een relatie verbindt twee tabellen met elkaar. Door deze relatie kunnen ze met elkaar communiceren. Met filterrichting kan men bepalen of deze communicatie vanuit een tabel komt of vanuit beide tabellen. Filterrichting kun je wel vergeleken met een deur. Op basis van de richting wordt bepaald welke tabel door de deur mag om te kunnen communiceren.
Single
Met de filterrichting ‘single’ staat de deur open voor de één-kolom ( vaak de dimensie). Dit betekent dat de veel-kolom (de feitentabel) niet kan communiceren met de één-kolom (vaak de dimensie). In deze situatie hebben andere dimensietabellen, die ook de feitentabel beïnvloeden, geen invloed op de huidige dimensietabel.
Beide-relatie
Met een beide-relatie kan zowel de veel-kolom (feitentabel) als de één-kolom (dimensietabel) met elkaar communiceren. Er wordt geadviseerd om deze vorm van relatie zoveel mogelijk te vermijden.
In een ster-, sneeuwvlok- of stervlokmodel wordt een feitentabel beïnvloed door meerdere dimensietabellen. Als de optie om de feitentabel met de dimensietabel te laten communiceren openstaat, ontstaat de kans dat andere dimensietabellen via de feitentabel de huidige dimensie tabel zal beïnvloeden. Op zijn beurt kan de huidige dimensietabel ook de feitentabel beïnvloeden en hierdoor wordt de kans op onduidelijke of foutieve data ernstig vergroot.
De uitzondering waarin een filterrichting ‘beide’ kan worden gebruikt, is als een van de twee tabellen, betroken in de relatie, geen andere relaties heeft of gaat krijgen. Of in het geval van het gebruik van een tussentabel waarbij de tussentabel zowel een beide-directie heeft met de feitentabel als een single-directie met de dimensie. De tussentabel kan niet communiceren met de dimensietabel en hierdoor eindigt de invloed van de beide-relatie.
Single met filterrichting
In het geval van een veel-op-veel relatie ontbreekt het Power BI aan unieke waarden. In dit geval zal Power BI automatisch voor een beide-relatie kiezen. In dit geval kan handmatig worden gekozen voor de filterrichting. Hier kan worden aangegeven welke tabel mag communiceren met de andere tabel. In het geval van veel-op-veel relaties wordt altijd aangeraden om de filterrichting te bepalen om beide-relaties te voorkomen.
4. De definitie van de architectuur van het semantic model in ster, sneeuwvlok of combinatie
In het proces van normalisatie worden grote gedenormaliseerde tabellen opgeknipt in meerdere kleinere tabellen. De mate van normaliseren, bepaalt uiteindelijk de architectuur van het semantic-model.
In relatie tot Power BI herkennen we drie model-architecturen. Het stermodel, het snowflakemodel en het stervlokmodel. Elk model heeft zijn eigen voor- en nadelen en is sterk afhankelijk van de mate waarin normalisatie mogelijk is.
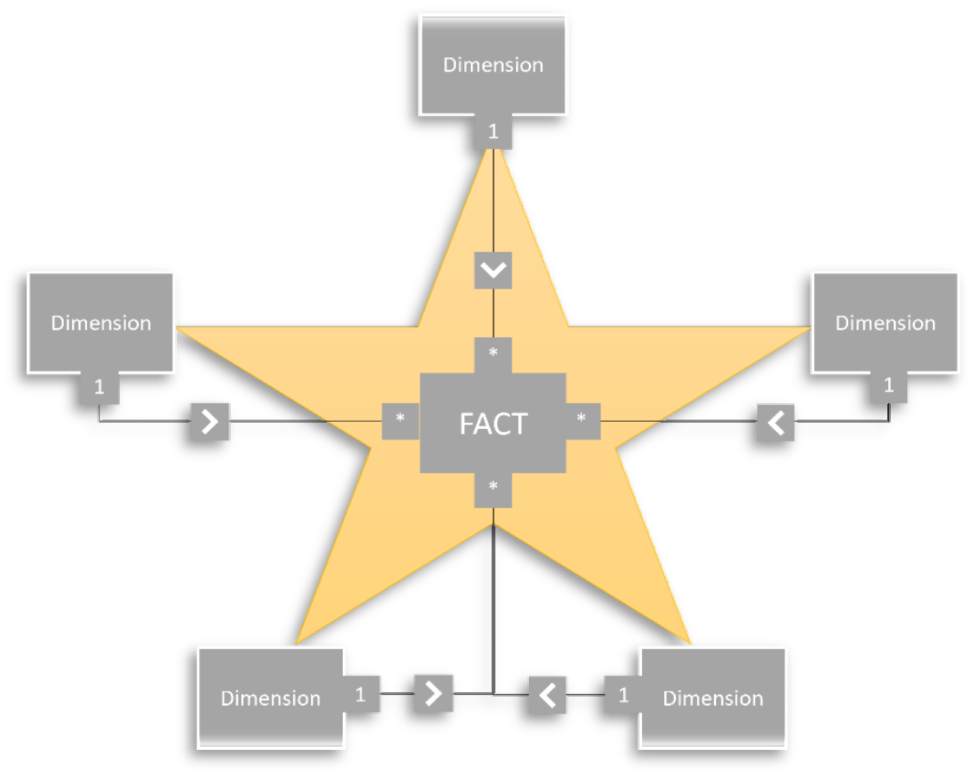
Stermodel
In het stermodel is de feitentabel genormaliseerd en zijn de dimensietabellen gedenormaliseerd. Deze feitentabel heeft een relatie met verschillende dimensietabellen, vaak via de relatie één-op-veel. In tegenstelling tot een snowflakemodel staan de dimensietabellen los van elkaar. Zij hebben dus geen relatie met elkaar.
De voordelen van een stermodel zijn:
Ontwerp:
- Het stermodel heeft een simpel en makkelijk te begrijpen ontwerp.
Query:
- Een snelle prestatie wegens de veel-op-één relaties.
Data:
- Geschikt voor grote hoeveelheden data.
De nadelen van een ster model zijn:
Overtollige data:
- De dimensietabellen in een stermodel zijn vaak gedenormaliseerd. Dit betekent dat de dimensietabellen in een stermodel zijn overtollige data opslaat in zijn dimensietabellen. Dit kan bij een groot datamodel onoverzichtelijk zijn.
Geen complexe relaties:
- Het sterschema heeft een beperkt vermogen om complexe relaties tussen feit en dimensie weer te geven.
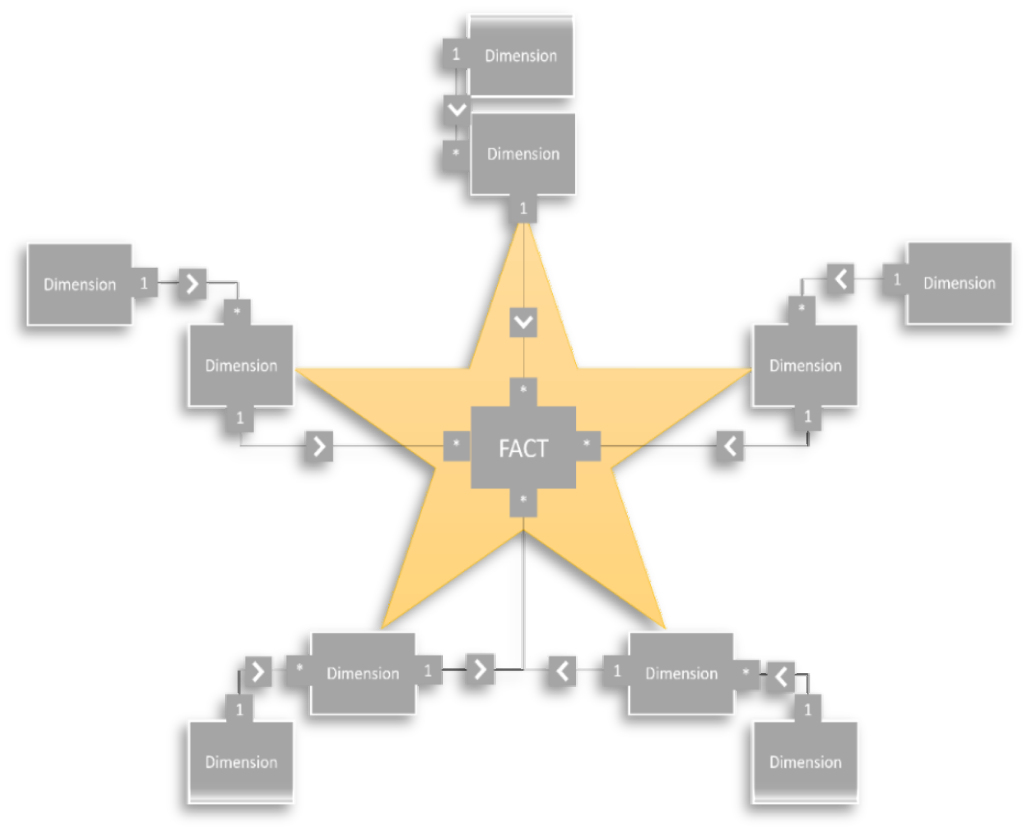
Snowflakemodel
Een snowflakemodel is bijna volledig genormaliseerd. Alle overtollige data (inclusief de overtollige data in dimensietabellen) zijn verspreid over meerdere dimensietabellen. In tegenstelling tot een stermodel kunnen de dimensietabellen in een snowflakemodel wel een relatie met elkaar hebben.
De voordelen van een snowflakemodel zijn:
Overtollige data:
- Een genormaliseerde datastructuur vermindert de overtollige gegevens.
Complexe relaties:
- Maakt complexere relaties tussen gegevens mogelijk.
Zoekopdrachten:
- Goed voor meer gestructureerde, voorspelbare zoekopdrachten.
De nadelen van een snowflakemodel zijn:
Ontwerp:
- De complexere datastructuur kan moeilijker te begrijpen en gebruiken zijn.
Query:
- Meerdere relaties tussen tabellen kunnen resulteren in langzamere queryprestaties.
Opslag:
- Vereist meer opslag vanwege het grotere aantal tabellen.
Starflakemodel
Een starflakemodel is een combinatie van een stermodel en een snowflakemodel. In een starflakemodel zijn maar een aantal dimensietabellen gedenormaliseerd. Een starflakemodel probeert de voordelen van stermodel en snowflake te combineren.
Tot slot
Om tot een goed en efficiënt datamodel te komen, is het belangrijk om het proces van normalisatie te begrijpen in combinatie met verschillende opties van relaties. In essentie betekent dit het opknippen van grote samenvattende tabellen (feiten) in kleinere opzoektabellen (dimensie). De mate van normalisatie bepaalt vaak het ontwerp van het datamodel. Een stervlokmodel heeft vaak een genormaliseerde feitentabel en gedenormaliseerde dimensietabellen. In een sneeuwvlokmodel zijn vaak ook de dimensietabellen genormaliseerd. Het streven is om een datamodel zo veel mogelijk te normaliseren, maar de mogelijkheid hiertoe is sterk afhankelijk van de input ( data ).
Een goed of fout datamodel is lastig te definiëren. Een datamodel is sterk afhankelijk van de kwaliteit van de input (data) die je erin stopt. Dit kan per bedrijf verschillen en het gevolg is dat er niet één harde waarheid bestaat over een juist datamodel. Om tot een goed datamodel in Power BI te komen, is het zeer belangrijk dat de juiste onderdelen worden begrepen en er hierdoor goed afgewogen keuzes worden gemaakt.




