Waarom je een veel-op-veel relatie wil voorkomen
Het datamodel is een belangrijk aspect van een goede Power BI-omgeving. Het is de weg waarop Power BI navigeert om tot een eindresultaat te komen. Het opstellen van een goed en efficiënt datamodel geeft voordelen op het gebied van prestatie, DAX-codering en foutoplossingen.
Een goed of fout datamodel is lastig te definiëren. Het is sterk afhankelijk van de kwaliteit van de input data die je erin stopt. Dit kan per bedrijf verschillen en het gevolg is dat er niet één harde waarheid bestaat over een juist datamodel.
Voor het opzetten van een Power BI-datamodel is het belangrijk om goed afgewogen keuzes te maken. Om je hierbij te helpen, licht ik in dit artikel, aan de hand van begrijpelijke voorbeelden, toe waarom je een ‘veel-op-veel’ relatie altijd moet vermijden.
Wat is een veel-op-veel relatie (*: *)
Veel-op-Veel betekent dat in de veel-kolom (feitentabel) een waarde meerdere keren voorkomt. In de één-kolom (vaak de dimensie) komt de waarde ook meerdere keer voor. Al valt deze vorm van relatie niet altijd te voorkomen, wordt aangeraden ze te vermijden. Bij deze vorm van relatie zal Power BI alles met alles vergelijken en hierdoor het aantal query’s op de achtergrond vermenigvuldigen. Bij veel-op-veel vergelijkingen kan deze relatie al snel voor prestatieproblemen zorgen.
Performance Analyzer en Dax Studio
Wat doet een veel-op-veel relatie onder water? Om die vraag te kunnen beantwoorden, is het noodzakelijk kennis te maken met de externe applicatie DAX Studio. Dat is een hulpmiddel voor het schrijven, uitvoeren en analyseren van DAX-query's. Daarnaast heeft het als optie Power BI metadata te analyseren aan de hand van SQL select statements. DAX Studio is vriendelijk in gebruik bij zowel grote als kleine Power BI-omgevingen. Het geeft inzicht en is ondersteunend aan het ontwikkelproces, en daardoor een must-have voor elke Power BI-ontwikkelaar.
Een van de vele opties van DAX Studio zijn ‘traceringen’. Dit zijn mechanismes om DAX-query’s te analyseren. De ‘traceringen’ bestaan uit drie mogelijkheden:
- Alle Query’s:
De Alle Query’s-tracering geeft een overzicht van alle gedraaide query’s, en dus niet alleen query's die vanuit DAX Studio worden verzonden, zoals Query Plan en Server Timings.
- Query Plan:
Query Plan traceert de SSAS Tabular server. Op moment van schrijven wordt deze tracering geretourneerd in een onduidelijk leesbaar format. Het vergt een bijzondere expertise om deze tracering te begrijpen en hierdoor is hij niet relevant voor dit artikel. Microsoft geeft wel aan dat er updates aan komen voor de leesbaarheid van deze tracering. Hopelijk gaat deze tracering daardoor meer toevoegen in de toekomst.
- Server Timings:
Server Timings is belangrijk voor onze analyse. Deze optie geeft het benodigde overzicht van het aantal query’s onder water en geeft hierbij ook de verstreken tijd en het CPU-percentage.
- Performance analyzer:
Om gebruik te kunnen maken van Server Timings, draai je eerst de Performance Analyzer in Power BI Desktop. De Performance Analyzer retourneert de DAX-query die Power BI gebruikt bij het uitvoeren van de taak. Let op: deze DAX-query is niet hetzelfde als een DAX-measure.
Casus
Om goed inzicht te krijgen in de prestatie van een veel-op-veel relatie, kan die het beste worden vergeleken met de prestatie van de één-op-veel relatie.
Één-op-veel betekent dat in de veel-kolom (feitentabel) een waarde meerdere keren kan voorkomen. In de één-kolom (vaak de dimensie) komt de waarde maar één keer voor. Dit is de meest voorkomende relatie en zal de beste prestaties opleveren. Power BI hoeft immers maar één waarde op te zoeken en matchen. Deze relatie wordt in beginsel altijd geadviseerd.
Ter illustratie zijn twee semantische modellen gecreëerd. Beide zijn identiek aan elkaar, waarbij het enige verschil de relatie kardinaliteit van één-op-veel naar veel-op-veel betreft.
De data betreft een simpele dimensietabel met categorie {A, B, C} en een feitentabel met meerdere terugkerende waarden {A, B, C} plus een hoeveelheid kolom.
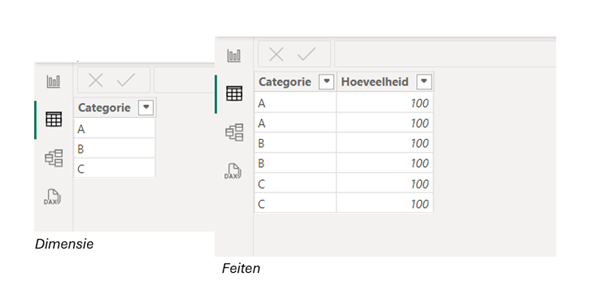
Daarnaast bestaat er nog een simpele tabel-visualisatie waarbij hoeveelheid wordt uitgesplitst naar categorie.

Wat doet een veel-op-veel relatie?
Het proces om de veel-op-veel relatie inzichtelijk te krijgen, begint met het draaien van de Performance Analyzer. Na het connecteren met DAX-Studio kan de Server Timing worden gedraaid met de query afkomstig uit de Performance Analyzer.
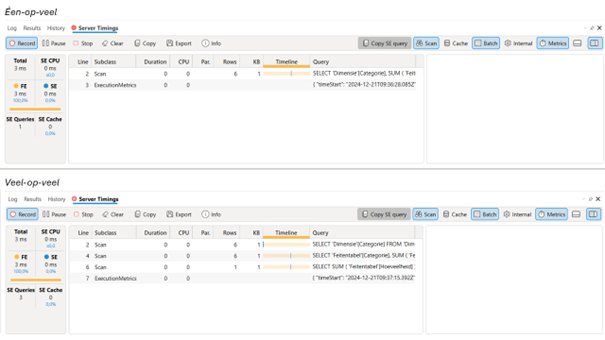
Alhoewel de Semantische Modellen identiek zijn, draait de Server Timing voor de één-op-veel relatie maar één scan query, terwijl de veel-op-veel relatie drie scan query’s retourneert. Dit verschil is te verklaren in het enige verschil tussen de semantische modellen, de kardinaliteit.
Één-op-veel
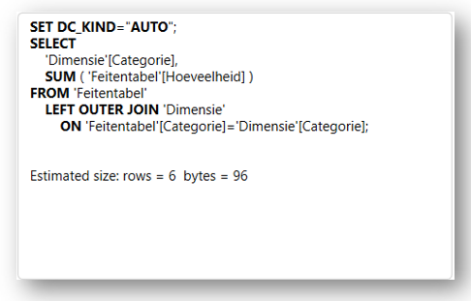
In het geval van de één-op-veel relatie retourneert Power BI één SQL select statement. Het selecteert de Dimensie [Categorie], omdat dit is aangegeven in de visual en dus telt als visual context. Daarnaast selecteert het de som van de Feitentabel [hoeveelheid], omdat dit is bepaald in de bijbehorende berekening. Om de som te alloceren over de bijbehorende categorieën, wordt gebruik gemaakt van een ‘left outer join’, waarbij de bijbehorende categorie uit de Feitentabel [Categorie] wordt gekoppeld aan de Dimensie [Categorie]. Door het gebruik van een ‘left outer join’ zijn ook null waarden zichtbaar.
In het geval van de één-op-veel relatie heeft Power BI één query gegenereerd, waarbij het alleen de Dimensie [Categorie] in het geheugen heeft gekopieerd.
Veel-op-veel
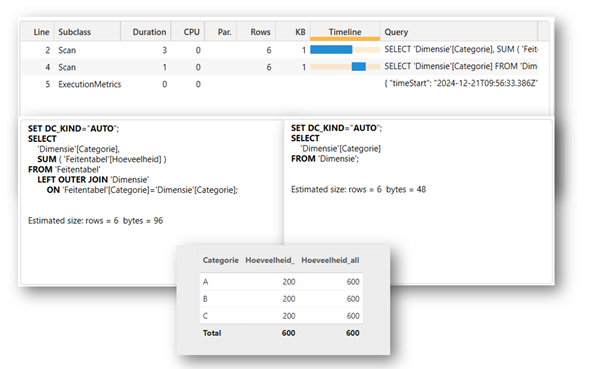
De veel-op-veel relatie geeft een ander beeld. Hier krijgt Power BI de opdracht om alles op alles te alloceren. Het begint hiermee door de volledige dimensietabel te kopiëren in het geheugen. De opdracht is immers alles-op-alles. De tweede query betreft een werkgeheugen kopie van de feitentabel waarbij het een ‘where’ statement toepast op Feitentabel [Categorie], met alle waardes uit de dimensietabel als filter context. Het heeft dan de feitentabel bepaald op basis van de waardes uit de dimensietabel. Als afsluitende query bepaalt het nog de som.
Uit bovenstaande analyse kan worden afgeleid dat men te allen tijde een veel-op-veel relatie wil vermijden, omdat bij een veel-op-veel óók geredeneerd wordt vanuit de feitentabel. In ons voorbeeld hebben wij heel weinig data en zal dit geen problemen opleveren, maar bij een groot datamodel met veel-op-veel relaties wordt, naast de dimensietabel, ook de feitentabel gekopieerd naar het geheugen. Dit moeten worden voorkomen om dezelfde reden dat er ook geen iteratie-functie op een feitentabel wordt gezet.

Bovenstaande analyse verklaart ook waarom de ALL-functie niet altijd werkt bij een veel-op-veel relatie.
ALL-functie werkt niet bij veel-op-veel relatie
Stel, De volgende berekening wordt gebruikt:
CALCULATE (SUM(‘FACT'[Amount]), ALL (‘FACT’))
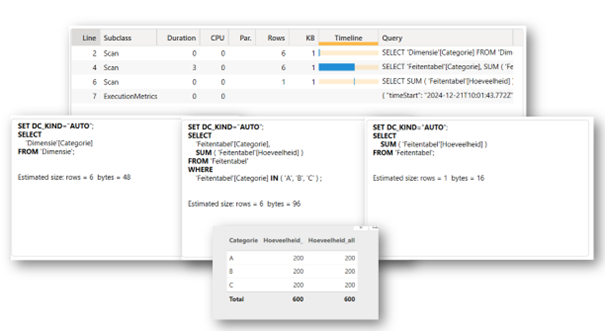
Één-op-veel
In het geval van de één-op-veel relatie zal Server Timing een extra query stap laten zien. De volledige kopie van de dimensietabel, zoals ook voorkomt bij de veel-op-veel relatie in het vorige voorbeeld. Dit is logisch, want veel-op-veel staat in principe gelijk aan de ‘ALL’ functie.
Veel-op-veel
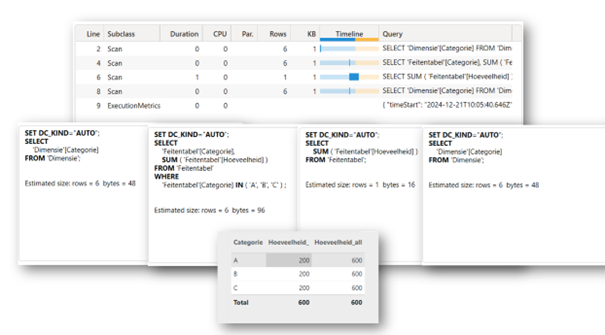
In het geval van veel-op-veel verandert er niets, behalve dat de berekening niet werkt in deze vorm. De query, waar de dimensietabel volledig in het werkgeheugen wordt gekopieerd, bestaat al. De desbetreffende query is immers nodig om de vervolg query, de kopie van de feitentabel, te realiseren. Beide query’s zijn nodig om de veel-op-veel relatie te garanderen. Power BI kan deze query dus niet opnieuw uitvoeren in het geval van een veel-op-veel relatie.
Als de ALL-functionaliteit op de dimensie wordt geplaats, gaat de veel-op-veel relatie eerst de drie query’s uitvoeren om de veel-op-veel relatie te realiseren om daarna de filters te verwijderen. Hierdoor voegt het nog één extra query toe, waarbij het dan toch uiteindelijk de dimensietabel volledig kopieert.
Conclusie
Alhoewel beide semantische modellen identiek zijn, kan een klein verschil als relatie kardinaliteit al een grote impact hebben. In bovenstaand voorbeeld draait Power BI bij de één-op-veel relatie maar één of twee query’s, terwijl bij de veel-op-veel relatie al drie tot vier query’s worden gedraaid. Hoe groter de dataset en het daar bijbehorende volume, des te groter de impact en negatieve gevolgen. Probeer een veel-op-veel relatie dan ook altijd te voorkomen!



